
{kind=link}
Users of ChatGPT in Europe can now use web forms or other means provided by OpenAI to request deletion of their personal data in order to stop the chatbot processing (and producing) information about them. They can also request an opt-out of having their data used to train its AIs.
Why might someone not want their personal data to become fodder for AI? There is a long list of possible reasons, not least the fact OpenAI never asked permission in the first place — despite privacy being a human right. Put another way, people may be concerned about what such a powerful and highly accessible technology could be used to reveal about named individuals. Or indeed take issue with the core flaw of large language models (LLMs) making up false information.
ChatGPT has quickly shown itself to be an accomplished liar, including about named individuals — with the risk of reputational damage or other types of harm flowing if AI is able to automate fake news about you or people close to you.
And just imagine what a highly trained mimic of how you personally converse might be able to do to you (or to your loved ones) were such an AI model to be misused.
Another batch of issues relate to intellectual property rights. If you have a white collar job you might be worried about generative AI driving push-button commercial exploitation of a particular writing style or some other core professional expertise which could make your own labor redundant or less valuable. And, again, the tech giants behind these AI models typically aren’t offering individuals any compensation for exploiting their data for profit.
You may also have a non-individual concern — such as the risk of AI chatbots scaling bias and discrimination — and simply wish for your information not to play any part.
Or perhaps you worry about the future of competitive markets and innovation if vast amounts of data continue to accumulate with a handful of tech giants in an era of data-dependent AI services. And while removing your own data from the pool is just a drop in an ocean it’s one way to register active dissent which could also encourage others to do the same — scaling into an act of collective protest.
Additionally, you might be uncomfortable your data is being used so opaquely — before more robust laws have been passed to govern how AI can be applied. So ahead of a proper legal governance framework for safe and trustworthy usage of such a powerful technology you may prefer to hold back your data; i.e. to wait until there are stronger checks and balances applied to generative AI operators.
While there are lots of reasons why individuals might want to shield their information from big data mining AI giants there are — for now — only limited controls on offer. And these limited controls are mostly only available to users in Europe where data protection laws do already apply.
Scroll lower down for details on how to exercise available data rights — or read on for the context.
From viral sensation to regulatory intervention
ChatGPT has been impossible to miss this year. The virality of the ask-it-anything “general purpose” AI chatbot has seen the tech travelling all over the mainstream media in recent months as commentators from across the subject spectrum kick its tyres and get wowed by a simulacrum of human responsiveness which, nonetheless, is not human. It’s just been trained on lots of our web-based chatter (among other data sources) to function as an accomplished mimic of how people communicate.
However the existence of such a capable-seeming natural language technology has directed attention onto the detail of how ChatGPT was developed.
Notably, the buzz around ChatPT has drawn particular attention from privacy and data protection regulators in the European Union — where an early intervention by Italy’s data protection watchdog at the end of March, acting on powers it has under the bloc’s General Data Protection Regulation (GDPR), led to a temporary suspension of ChatGPT at the start of last month.
A major concern raised by the watchdog is whether OpenAI used people’s data lawfully when it developed the technology. And it is continuing to investigate this question.
Italy’s watchdog has also taken issue with the quality of information OpenAI provides about how it’s using people’s data. Without proper disclosures there are questions about whether it’s meeting the GDPR’s fairness and accountability requirements, too.
Additionally, the regulator has said it’s worried about the safety of minors accessing ChatGPT. And it wants the company to add age verification tech.
The bloc’s General Data Protection Regulation (GDPR) also provides people in the region with a suite of data control rights — such as the ability to ask for incorrect info about them to be corrected or for their data to be deleted. And if we’ve learnt anything about AI chatbots over the last few months it’s how readily they lie. (Aka “hallucinate” in techno-solutionist speak).
Shortly after Italy’s DPA stepped in to warn OpenAI that it suspected a series of GDPR breaches, the company launched some new privacy tools — giving users a button to switch off a chat history feature which logged all their interactions with the chatbot, saying this would result in conversations started when the history feature had been disabled not being used to train and improve its AI models.
That was followed by OpenAI making some privacy disclosures and presenting additional controls — timed to meet a deadline set by the Italian DPA for it to implement a preliminary package of measures in order to comply with the bloc’s privacy rules. The upshot is OpenAI now provides web users with some say over what it does with their information — although most of the concessions it’s offered are region-specific. So the first step to protecting your information from big data-driven AI miners is to live in the Europe Union (or European Economic Area), where data protection rights exist and are being actively enforced.
As it stands, UK citizens still benefit from the EU data protection framework being embedded in their national law — so also have the full sweep of GDPR rights — although the government’s post-Brexit reforms look set to water down the national data protection regime, so it remains to be seen how the domestic approach might change. (UK ministers also recently signalled they don’t intend to bring in any bespoke rules for applying AI for the foreseeable future.)
Beyond Europe, Canada’s privacy commissioner is investigating complaints about the technology. Other countries have passed GDPR-style data protection regimes so powers exist for regulators to flex.
How to ask OpenAI to delete personal data about you
OpenAI has said that individuals in “certain jurisdictions” (such as the EU) can object to the processing of their personal information by its AI models by filling out this form. This includes the ability to make requests for deletion of AI-generated references about you. Although OpenAI notes it may not grant every request since it must balance privacy requests against freedom of expression “in accordance with applicable laws”.
The web form for making a deletion of data about you request is entitled “OpenAI Personal Data Removal Request”. Here’s the link to it:
Web users are asked to provide it with their contact data and details of the data subject for whom the request is being made; the country whose laws apply in this person’s case; to specify whether they are a public figure or not (and if the former, to provide more context about what type of public figure they are); to provide evidence of data processing in the form of prompts that generated responses from the model which mentioned the data subject and screenshots of relevant outputs.
Users are also asked to make sworn statements that the information provided is accurate and acknowledge that incomplete submissions may not be acted upon by OpenAI prior to submitting the form.
The process is similar to the ‘right to be forgotten’ web form Google has provided for years — initially for Europeans seeking to exercise GDPR rights by having inaccurate, outdated or irrelevant personal data delisted from its search engine results.
The GDPR provides individuals with several rights other than requesting data deletion — such as asking for their information to be corrected, restricted, or for a transfer of their personal data.
OpenAI stipulates that individuals can seek to exercise such rights over personal information that may be included in its training information by emailing dsar@openai.com. However the company told the Italian regulator that correcting inaccurate data generated by its models is not technically feasible at this point. So it will presumably respond to emailed requests for a correction of AI-generated disinformation by offering to delete personal data instead. (But if you’ve made such a request and had a respond from OpenAI get in touch by emailing tips@techcrunch.com.)
In its blog post, OpenAI also warns that it could deny (and/or otherwise only partially act on) requests for other reasons, writing: “Please be aware that, in accordance with privacy laws, some rights may not be absolute. We may decline a request if we have a lawful reason for doing so. However, we strive to prioritize the protection of personal information and comply with all applicable privacy laws. If you feel we have not adequately addressed an issue, you have the right to lodge a complaint with your local supervisory authority.”
How the company handles Europeans’ Data Subject Access Requests (DSARs) may determine whether ChatGPT faces a wave of user complaints which could lead to more regulatory enforcement in the region in future.
Since OpenAI has not established a local legal entity that’s responsible for its processing of EU user data, watchdogs in any Member State are empowered to act on concerns on their patch. Hence Italy’s quick action.
How to ask OpenAI not to use your data for training AIs
Following the Italian DPA’s intervention OpenAI revised its privacy policy to state that the legal basis it relies upon for processing people’s data to train its AIs is something that’s referred to in the GDPR as “legitimate interests” (LI).
In its privacy policy, OpenAI writes that its legal bases for processing “your Personal Information” include [emphasis ours]:
Our legitimate interests in protecting our Services from abuse, fraud, or security risks, or in developing, improving, or promoting our Services, including when we train our models. This may include the processing of Account Information, Content, Social Information, and Technical Information.
There is still a question mark over whether relying on LI for a general purpose AI chatbot will be deemed an appropriate and valid legal basis for the processing under the GDPR, as the Italian watchdog (and others) continues to investigate.
These detailed investigations are likely to take some time before we have any final decisions — which could, potentially, lead to orders that it stop using LI for this processing (which would leave OpenAI with the option of asking users for their consent, complicating its ability to develop the technology at the kind of scale and velocity it has to date). Although EU DPAs may ultimately decide its use of LI in this context is okay.
In the meanwhile, OpenAI is legally required to provide users with certain rights as a consequence of its claim to be relying upon LI — notably this means it must offer a right to object to the processing.
Facebook was also recently forced to offer such an opt out to European users — i.e. to its processing of their data for targeting behavioral ads — also after switching to claiming LI as its legal basis for processing people’s information. (Additionally the company is facing a class action style lawsuit in the UK for its prior failure to offer an opt out for ad targeting processing, given the GDPR contains an absolute requirement for any data processing for direct marketing — which perhaps goes some way to explaining OpenAI’s keenness to emphasize it’s not in the same business as adtech giant Facebook, hence its claim that: “We don’t use data for selling our services, advertising, or building profiles of people — we use data to make our models more helpful for people.”)
In its privacy policy, the ChatGPT maker makes a passing acknowledgement of the objection requirements attached to relying on LI, pointing users towards more information about requesting an opt out — when it writes: “See here for instructions on how you can opt out of our use of your information to train our models.”
This link opens to another blog post where it promotes the notion that AI will “improve over time”, at the same time as encouraging users not to exercise their right to object to the personal data processing by claiming that “shar[ing] your data with us… helps our models become more accurate and better at solving your specific problems and it also helps improve their general capabilities and safety”. (But, well, can we call it sharing data if the stuff was already taken without asking?)
OpenAI then offers users a couple of choices for opting out their data out of its training: Either via (another) web form or directly in account settings.
You can opt out of your data being used to train its AI by filling in this web form — which is for individual users of ChatGPT — and called a “User content opt out request”.
Users can also disable training on their data via ChatGPT account settings (under “Data Controls”). Assuming they have an account.
But — be warned! — the settings route to opt out is replete with dark patterns seeking to discourage the user from shutting off OpenAI’s ability to use their data to train its AI models.
(And in neither case is it clear how non-users of ChatGPT can opt out of their data being processed since the company either requires you have an account or requests your account details via the form; so we’ve asked it for clarity.)
To find the Data Controls menu you click on the three dots next to your account name at the bottom left of the screen (under the chat history bar); then click “Settings”; then click to “Show” the aforementioned Data Controls (nice dark pattern hiding this toggle!); then slide the toggle to switch off “Chat History & Training”.
To say OpenAI is discouraging users from using the settings route to opt out of training is an understatement. Not least because it’s linked this action to the inconvenience of losing access to your ChatGPT history. But the moment you toggle it back on your chats reappear (at least if you re-enable history within 30 days, per its previously disclosed data retention policy.)
Additionally, after you’ve disabled training the sidebar of your historical chats is replaced by a brightly colored button that’s displayed around the eyeline which sits there permanently nudging users to “Enable chat history”. There’s no mention on this button that clicking it toggles back on OpenAI’s ability to train on your data. Instead OpenAI has found space for a meaningless power button icon — presumably as another visual trick to encourage users to power up the feature so it can regain access to their data.
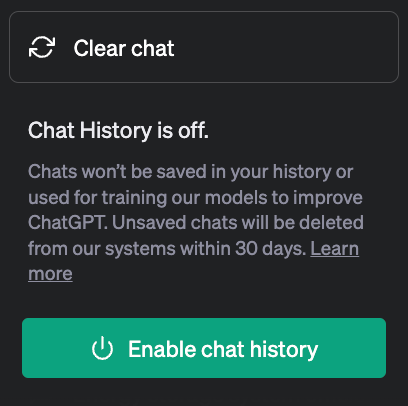
Image credit: Natasha Lomas/TechCrunch
Given that users who opt for the settings method to block training will lose ChatGPT’s chat history functionality, submitting the web form looks to offer a better path — since, in theory, you might be able to retain the functionality despite asking for your conversations not to be training fodder. (And, at the least, you have recorded your objection in a formal format which should perhaps count for more than toggling on/off a bright green button.)
That said, at the time of writing it’s not clear whether OpenAI will, in the case of objecting via the form, disable chat history functionality anyway, once it’s processed a web form submission asking for data not to be used for training AIs. (Again, we’ve asked the company for clarity on this point and will update this report if we get it.)
There’s a further caveat in OpenAI’s blog post — where it writes of opting out that:
We retain certain data from your interactions with us, but we take steps to reduce the amount of personal information in our training datasets before they are used to improve our models. This data helps us better understand user needs and preferences, allowing our model to become more efficient over time.
So it’s also not even clear what exact personal data are being firewalled from its training pool when users ask for their info not to be AI training fodder vs other types of information you input which it may still carry on processing anyway…
In short, this smells like fudge. (Or what’s known in the industry as compliance theatre.)
Thing is, the GDPR has a broad definition of personal data — meaning it’s not just direct identifiers (such as names and email addresses) which fall under the regulation’s framework but many types of information that could be used and/or combined to identify a natural person. So that means another key question here is how much of a reduction is OpenAI actually applying to its data processing activities when users opt out? Transparency and fairness are other key principles within the GDPR. So these sorts of questions are likely to keep European data protection agencies busy for the foreseeable future.