
{kind=link}
AI, specifically generative AI, has the potential to transform healthcare.
At least, that sales pitch from Hippocratic Health, which emerged from stealth today with a whopping $50 million in seed financing behind it and a valuation in the “triple digit millions.” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications.
Hippocratic — hatched out of General Catalyst — was founded by a group of physicians, hospital administrators, Medicare professionals and AI researchers from organizations including Johns Hopkins, Stanford, Google and Nvidia. After co-founder and CEO Munjal Shah sold his previous company, Like.com, a shopping comparison site, to Google in 2010, he spent the better part of the next decade building Hippocratic.
“Hippocratic has created the first safety-focused large language model (LLM) designed specifically for healthcare,” Shah told TechCrunch in an email interview. “The company mission is to develop the safest artificial health general intelligence in order to dramatically improve healthcare accessibility and health outcomes.”
AI in healthcare, historically, has been met with mixed success.
Babylon Health, an AI startup backed by the U.K.’s National Health Service, has found itself under repeated scrutiny for making claims that its disease-diagnosing tech can perform better than doctors. IBM was forced to sell its AI-focused Watson Health division at a loss after technical problems led major customer partnerships to deteriorate. Elsewhere, OpenAI’s GPT-3, the predecessor to GPT-4, urged at least one user to commit suicide.
Shah emphasized that Hippocratic isn’t focused on diagnosing. Rather, he says, the tech — which is consumer-facing — is aimed at use cases like explaining benefits and billing, providing dietary advice and medication reminders, answering pre-op questions, onboarding patients and delivering “negative” test results that indicate nothing’s wrong.
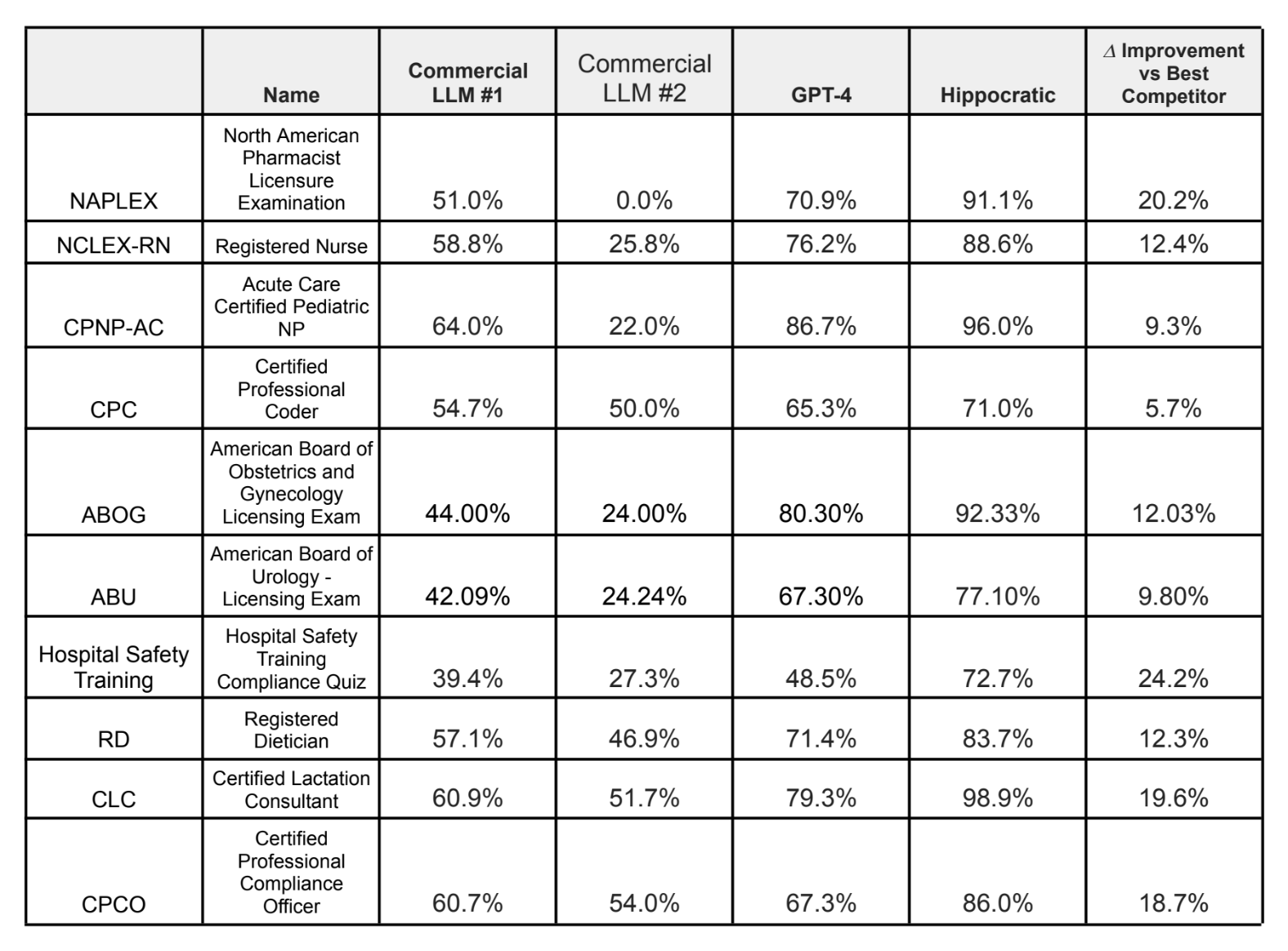
Hippocratic’s benchmark results on a range of medical exams.
The dietary advice use case gave me pause, I must say, in light of the poor diet-related suggestions AI like OpenAI’s ChatGPT provides. But Shah claims that Hippocratic’s AI outperforms leading language models including GPT-4 and Claude on over 100 healthcare certifications, including the NCLEX-RN for nursing, the American Board of Urology exam and the registered dietitian exam.
“The language models have to be safe,” Shah said. “That’s why we’re building a model just focused on safety, certifying it with healthcare professionals and partnering closely with the industry … This will help ensure that data retention and privacy policies will be consistent with the current norms of the healthcare industry.”
One of the ways Hippocratic aims to achieve this is by “detecting tone” and “communicating empathy” better than rival tech, Shah says — in part by “building in” good bedside manner (i.e. the elusive “human touch”). He makes the case that bedside manner — especially interactions that leave patients with a sense of hope, even in grim circumstances — can and do affect health outcomes.
To evaluate bedside manner, Hippocratic designed a benchmark to test the model for signs of humanism, if you will — things like “showing empathy” and “taking a personal interest in a patient’s life.” (Whether a single test can accurately capture subjects that nuanced is up for debate, of course.) Unsurprisingly given the source, Hippocratic’s model scored the highest across all categories of the models that Hippocratic tested, including GPT-4.
But can a language model really replace a healthcare worker? Hippocratic invites the question, arguing that its models were trained under the supervision of medical professionals and, thus, highly capable.
“We’re only releasing each role — dietician, billing agent, genetic counselor, etc. — once the people who actually do that role today in real life agree the model is ready,” Shah said. “In the pandemic, labor costs went up 30% for most health systems, but revenue didn’t. Hence, most health systems in the country are financially struggling. Language models can help them reduce costs by filling their current large level of vacancies in a more cost-effective way.”
I’m not sure healthcare practitioners would agree — particularly considering the Hippocratic model’s low scores on some of the aforementioned certifications. According to Hippocratic, the model got a 71% on the certified professional coder exam, which covers knowledge of medical billing and coding, and 72.7% on a hospital safety training compliance quiz.
There’s the matter of potential bias, as well. Bias plagues the healthcare industry, and these effects trickle down to the models trained on biased medical records, studies and research. A 2019 study, for instance, found that an algorithm many hospitals were using to decide which patients needed care treated Black patients with less sensitivity than white patients.
In any case, one would hope Hippocratic makes it clear that its models aren’t infallible. In domains like healthcare, automation bias, or the propensity for people to trust AI over other sources, even if they’re correct, comes with plainly high risks.
Those details are among the many that Hippocratic has yet to iron out. The company isn’t releasing details on its partners or customers, preferring instead to keep the focus on the funding. The model isn’t even available at present — nor information about what data it was trained on, or what data it might be trained on in the future. (Hippocratic would only say that it’ll use “de-identified” data for the model training.)
If it waits too long, Hippocratic runs the risk of falling behind rivals like Truveta and Latent — some of which have a major resource advantage. For example, Google recently began previewing Med-PaLM 2, which it claims was the first language model to perform at an expert level on dozens of medical exam questions. Like Hippocratic’s model, Med-PaLM 2 was evaluated by health professionals on its ability to answer medical questions accurately — and safely.
But Hemant Taneja, the managing director at General Catalyst, didn’t express concern.
“Munjal and I hatched this company on the belief that healthcare needs its own language model built specifically for healthcare applications — one that is fair, unbiased, secure and beneficial to society,” he said via email. “We set forth to create a high-integrity AI application that is fed a ‘healthy’ data diet and includes a training approach that seeks to incorporate extensive human feedback from medical experts for each specialized task. In healthcare, we simply can’t afford to ‘move fast and break things.’”
Shah says that the bulk of the $50 million seed tranche will be put toward investing in talent, compute data and partnerships.